

DIFFERENCES BETWEEN SQL SERVER CLUSTERED INDEX SCAN AND INDEX SEEK
Index scan means it retrieves all the rows from the table and index seek means it retrieves selective rows from the table.
INDEX SCAN:
Index Scan touches every row in the table it is qualified or not, the cost is proportional to the total number of rows in the table.
Thus, a scan is an efficient strategy if the table is small or most of the rows qualify for the predicate.
INDEX SEEK:
Index Seek only touches rows that qualify and pages that contain these qualifying rows.
The cost is proportional to the number of qualifying rows and pages rather than the total number of rows in the table.
They are two types of Indexes are there:
1. Clustered Index.
2. Non Clustered Index.
Clustered Index:
A non-clustered index can consist of one or more columns, but the data storage is not dependent on this create index statement as is the case with the clustered index.
For a table without a clustered index, which is called a heap, the non-clustered index points the row (data).
In the circumstance where the table has a clustered index, then the non-clustered index points to the clustered index for the row (data).
Although many implementations only have a single column for the clustered index, in reality a clustered index can have multiple columns.
Just be careful to select the correct columns based on how the data is used. The number of columns in the clustered (or non-clustered) index can have significant performance implications with heavy INSERT, UPDATE and DELETE activity in your database.
Must read: 7 Ways To Migrate On-Premise SQL Database To Azure
Let’s take a look. First, create an employee table inside GeoPITS executing the following script:
CREATE DATABASE GeoPITS
CREATE TABLE Employee
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
DOB datetime NOT NULL,
city VARCHAR(50) NOT NULL
)
Notice here in the “Employee” table we have set primary key constraint on the “id” column. This automatically creates a clustered index on the “id” column.
To see all the indexes on a particular table execute “sp_helpindex” stored procedure. This stored procedure accepts the name of the table as a parameter and retrieves all the indexes of the table. The following query retrieves the indexes created on student table.
USE GeoPITS
EXECUTE sp_helpindex Employee
The above query will return this result:

In the output you can see the only one index. This is the index that was automatically created because of the primary key constraint on the “id” column.
Another way to view table indexes is by going to “Object Explorer-> Databases-> Database_Name-> Tables-> Table_Name -> Indexes”. Look at the following screenshot for reference.
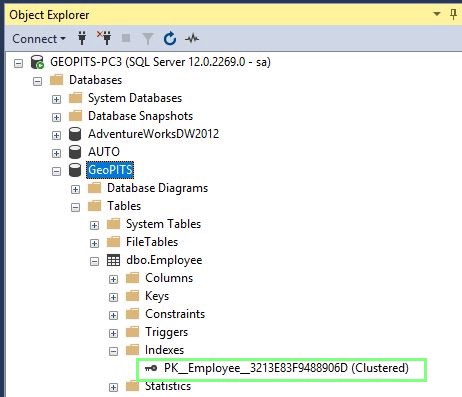
Non Clustered Index:
A non clustered index can consist of one or more columns, but the data storage is not dependent on this create index statement as is the case with the clustered index.
For a table without a clustered index, which is called a heap, the non clustered index points the row (data).
In the circumstance where the table has a clustered index, then the non clustered index points to the clustered index for the row (data).
In terms of the number of non clustered indexes, a single table can have up to 999 non clustered indexes. Although, too much of a good thing can become bad.
Keep in mind that SQL Server needs to keep the indexes updated as you INSERT, UPDATE and/or DELETE data.
As such, it is necessary to strike a balance with the number of indexes created for each table based on the activity on the table i.e. SELECT, INSERT, UPDATE and/or DELETE transactions.
When a query is issued against a column on which the index is created, the database will first go to the index and look for the address of the corresponding row in the table.
It will then go to that row address and fetch other column values. It is due to this additional step that non-clustered indexes are slower than clustered indexes.
Must read: 7 Key security features available in SQL Azure
Creating Non-Clustered Index:
The syntax for creating a non-clustered index is similar to that of clustered index. However, in case of non-clustered index keyword “NON-CLUSTERED” is used instead of “CLUSTERED”. Take a look at the following script.
use GeoPITS
CREATE NONCLUSTERED INDEX IX_tblEmployee_Name
ON Employee(name ASC)
The above script creates a non-clustered index on the “name” column of the Employee table. The index sorts by name in ascending order. As we said earlier, the table data and index will be stored in different places.
The table records will be sorted by a clustered index if there is one. The index will be sorted according to its definition and will be stored separately from the table.
Employee Table Data:
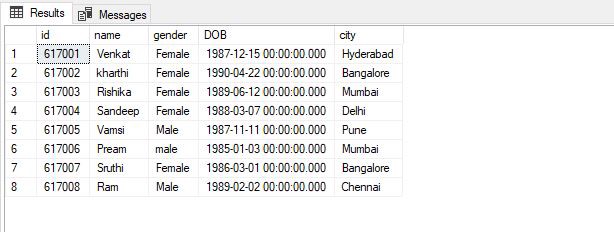
IX_tblEmployee_Name Index Data:

Notice, here in the index every row has a column that stores the address of the row to which the name belongs. So if a query is issued to retrieve the Id and City of the Employee named “Kharthi”, the database will first search the name “Kharthi” inside the index. It will then read the row address of “Kharthi” and will go directly to that row in the “Employee” table to fetch Id and City of Kharthi.
From this discussion we will find the following differences between Clustered index and Non-Clustered index are:
There can be only one clustered index per table. However, you can create multiple non-clustered indexes on a single table.
Clustered indexes only sort tables. Therefore, they do not consume extra storage. Non-clustered indexes are stored in a separate place from the actual table claiming more storage space.
Clustered indexes are faster than non-clustered indexes since they don’t involve any extra lookup step.
SQL Server Clustered Index Scan:
SQL Server Clustered Index Scan operator then try to understand different reason for which SQL Server optimizer picks up this to be the efficient plan operator to return intended records from a table. GeoPITS is the database used in this example.
- SCRIPT # 1
Select * from table name (geopits1)
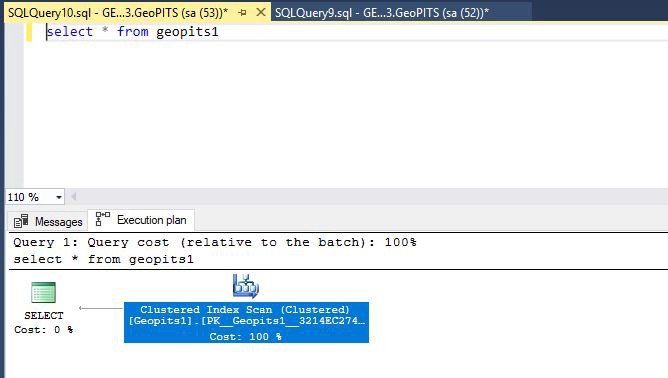
Considering the simple statement used for this demonstration against AdventireWorks2012 database, SQL Server optimizer decided to perform Clustered Index Scan operation.
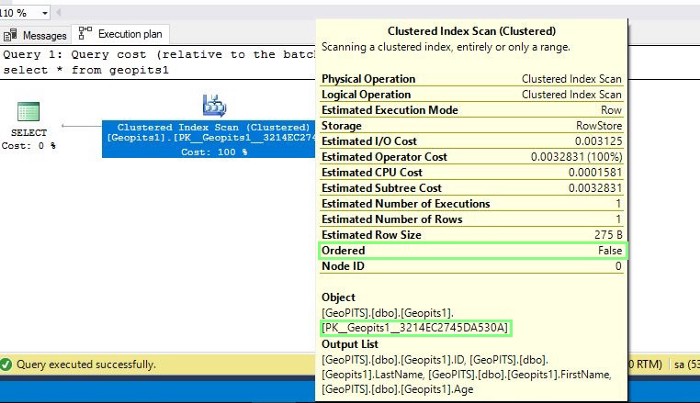
When we place mouse pointer to Clustered Index Scan operator it brings up ToolTip window where we can see that, clustered index PK_Geopits1_3214EC2745DA530A was used for this operation.
Clustered Index in SQL Server not only stores structure of the key, it also stores and sorts the data.
We can say, a Clustered Index Scan is same like a Table Scan operation i.e. entire index is traversed row by row to return the data set.
If the SQL Server optimizer determines there are so many rows need to be returned it is quicker to scan all rows than to use index keys.
Important point to note here is, though it seems both Table Scan and Clustered Index Scan to be similar operations, but former is used for heaps and the later one is used for Clustered Indexes.
Using a Clustered Index Scan does not guarantee that results will be sorted and we can observe the same in the ToolTip earlier and is highlighted in red (Ordered property is False).
Let us now quickly verify how the behavior changes when we explicitly add ORDER BY clause in our statement.
- SCRIPT # 2:
Select * from table name (geopits1)
Order by column name (id)
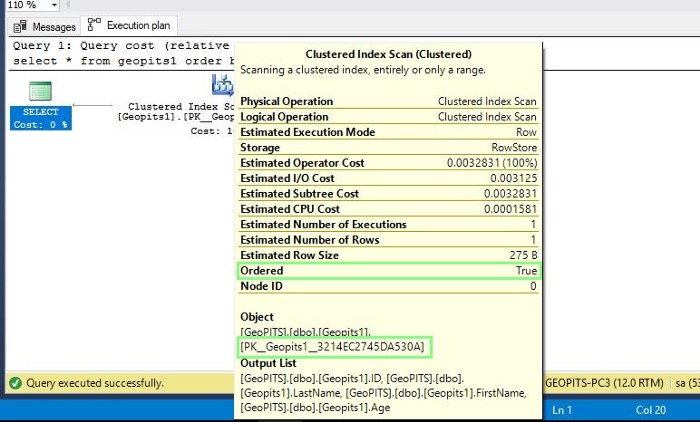
SQL Server Clustered Index Seek:
Let us look at Clustered Index Seek operator today. The statement below shows an example of SQL Server Index Seek (clustered) and of course database is GeoPITS.
SCRIPT # 3:
Select column name (id, Lastname, Firstname, age)
From table name(geopits1)
Where id = 617005

An index seek does not scan entire index, instead it navigates the B-tree structure to find one or more records quickly.
An Index Seek be it clustered or non-clustered takes place when SQL Server query optimizer able to locate an appropriate index to fetch required records that is, it sends an instruction to SQL engine to look up values based on the index keys.
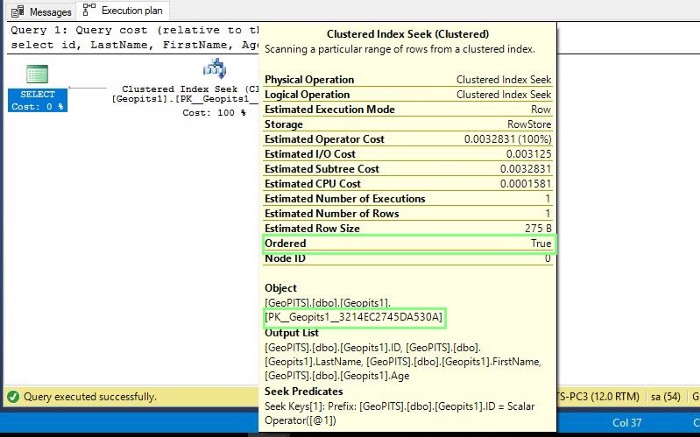
A clustered index stores key structure as well as the data itself. In our example, we have a clustered index seek operation against Geopits1 table and index used here is PK_Geopits1_3214EC2745DA530A.
ToolTip shows Ordered property is true indicating data is ordered by SQL Server query optimizer.
Further reading:
If you found this article helpful, you might want to check out these related resources,





