
MongoDB is known for its ability to store huge volumes of data. This makes MongoDB an ideal choice for a variety of use cases including big data analytics and artificial intelligence. To store huge volumes of different types of data in a distributed environment, MongoDB supports both horizontal and vertical scaling, and provides high availability and redundancy, while ensuring data consistency. MongoDB further goes up one level to also provide auto scaling.
What is scaling in a database?
A database is known to be scalable if it can adjust its resources constantly to meet the application requirements. For example, if your application is going through a high demand period, the database should be able to expand and provide more resources to ensure seamless transactions, and when the resources are no longer required, it should delete those resources to save memory space.
Before deciding to scale the database, you must ensure that your application and database are optimized i.e. optimize the application code, indexing and caching. Optimization reduces the load on the CPU and memory, saves storage and supports the network traffic. However, as your application’s demand keeps growing, the system resources might all reach their maximum limit. That is where you must scale your database - horizontally or vertically or both.
Types of scaling
You may need to scale your applications horizontally or vertically or use both these types, as your application demands.
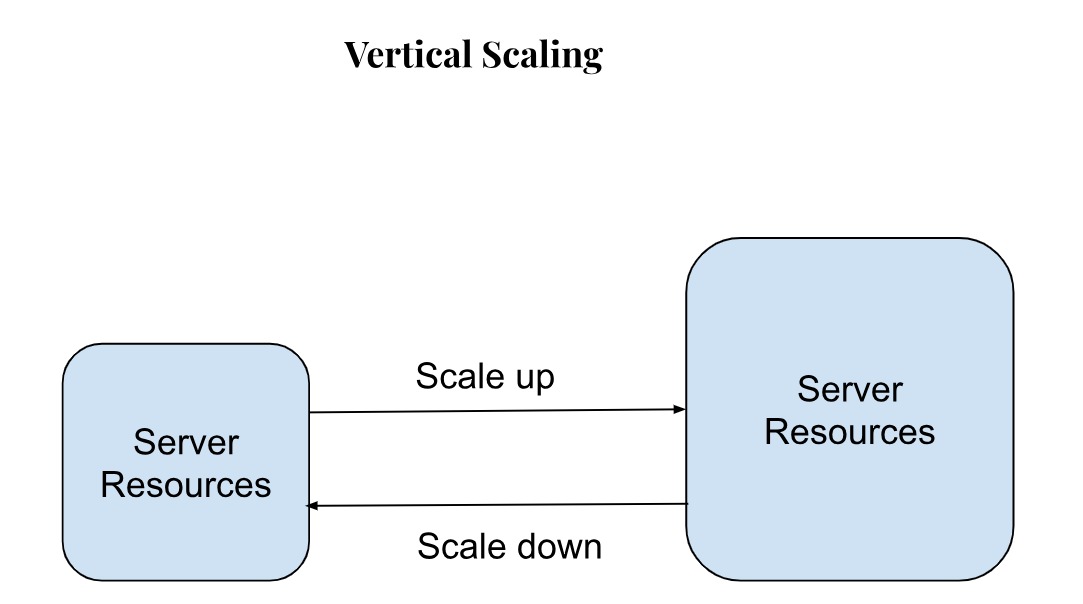
Vertical scaling
In this type, the capacity of a single cluster or server is increased to accommodate more incoming requests. All the databases - relational and non-relational have the capacity for vertical scaling, however even that has a limit and depends upon the maximum processing power and throughput.
Vertical scaling is also known as ‘scaling up’ the application, and involves upgrading the RAM or CPU of a single server to increase its capacity and hence speed.
Vertical scaling is easy and needs no change in your database infrastructure, which makes it an economical choice as well. Only one server (machine) is impacted by increasing or decreasing its capacity, so the maintenance is also easy.
However, there is a physical limit to how much you can expand a single machine’s memory, CPU, RAM and network interfaces.
Horizontal scaling
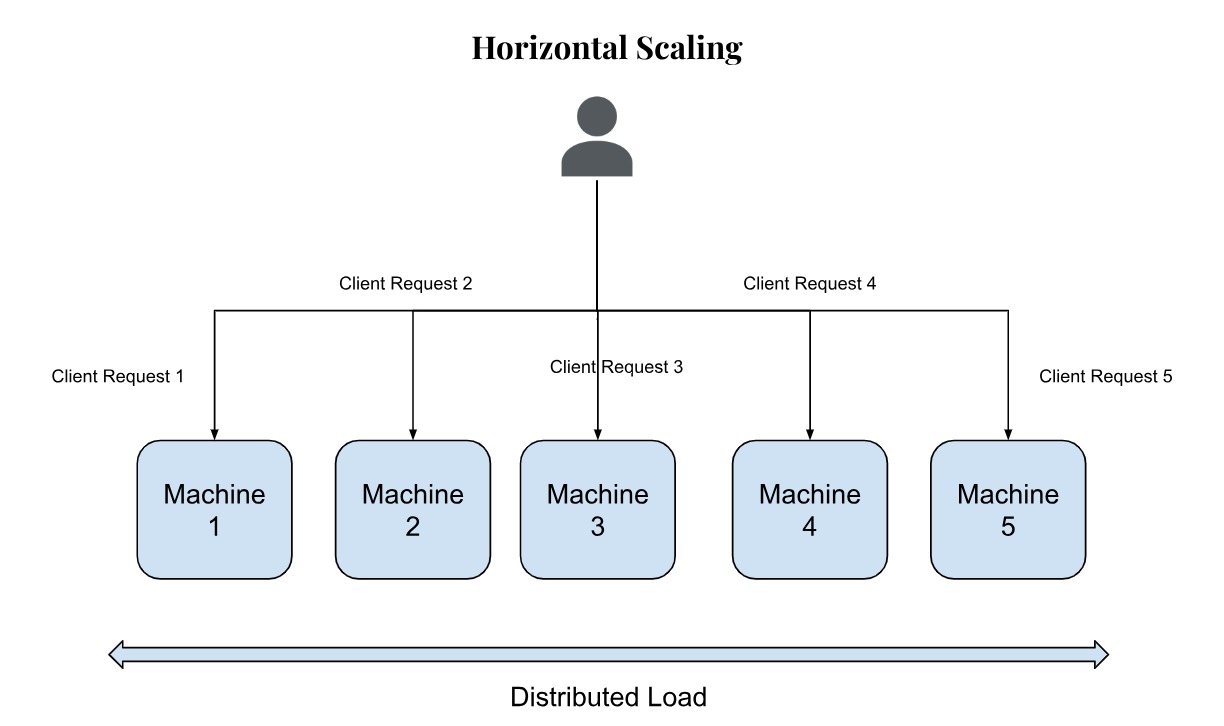
There is a limit to how much a single machine (server) can handle in terms of its own physical capacity. If the application requirements are not met with vertical scaling due to physical limits, you need to consider horizontal scaling or “scaling out”, where-in more machines are added to distribute the database load and increase the processing power and storage. You can keep adding as many resources as required and so there is no physical limitation - while this means better performance, it also means additional cost and architectural changes to the application code due to the distribution of data into several machines.
Horizontal scaling ensures more availability and redundancy, as if one of the machines (instances) goes down, you still have others that can process an incoming request.
That said, you cannot keep adding instances blindly, rather plan for concurrency or data partitioning to achieve higher database performance.
Why is scaling important?
Most modern applications are data-driven and quickly require ability to store and process more. Further, if you are a startup, you may not need so many resources initially, but as your business grows, you need to provide consistent performance. At a critical time when your business is expanding, you cannot afford to have downtime issues, data unavailability, and server issues - imagine your database running out of storage and refusing to respond to further requests – too bad!
How does MongoDB handle scaling issues?
MongoDB supports both horizontal and vertical scaling to keep up the performance of an application. The two methods used by MongoDB for horizontal scaling of an application are sharding and replication. Both the methods use the concept of a node i.e. single machine that stores data, and cluster, i.e. a collection of nodes.
Replication
MongoDB Atlas provides replication by default. Replication, as the name suggests, means creating copies of the database or the database node. Each node is a physically isolated server.
Each node of the cluster contains the same data, hence if one node goes down (unavailable), any request can still be handled by other nodes. This makes the system fault-tolerant and highly available, without any additional setup. Also, when all the nodes are up and running, client requests can be routed and distributed across nodes, such that there is no overloading on a single node. Thus, the database can handle more requests at any time.
So, what if one request writes data to one node, and another to another node and so on?
If multiple nodes handle different write requests, this would lead to inconsistent data!
To handle this, MongoDB has a concept of primary node and replica sets. In a cluster, there is only one primary node, and all the other replicated nodes or replica sets are the secondary nodes. Any application can read from any of the nodes, however a ‘write’ operation can be performed only to the primary node. The primary node then updates the changes to the other nodes.
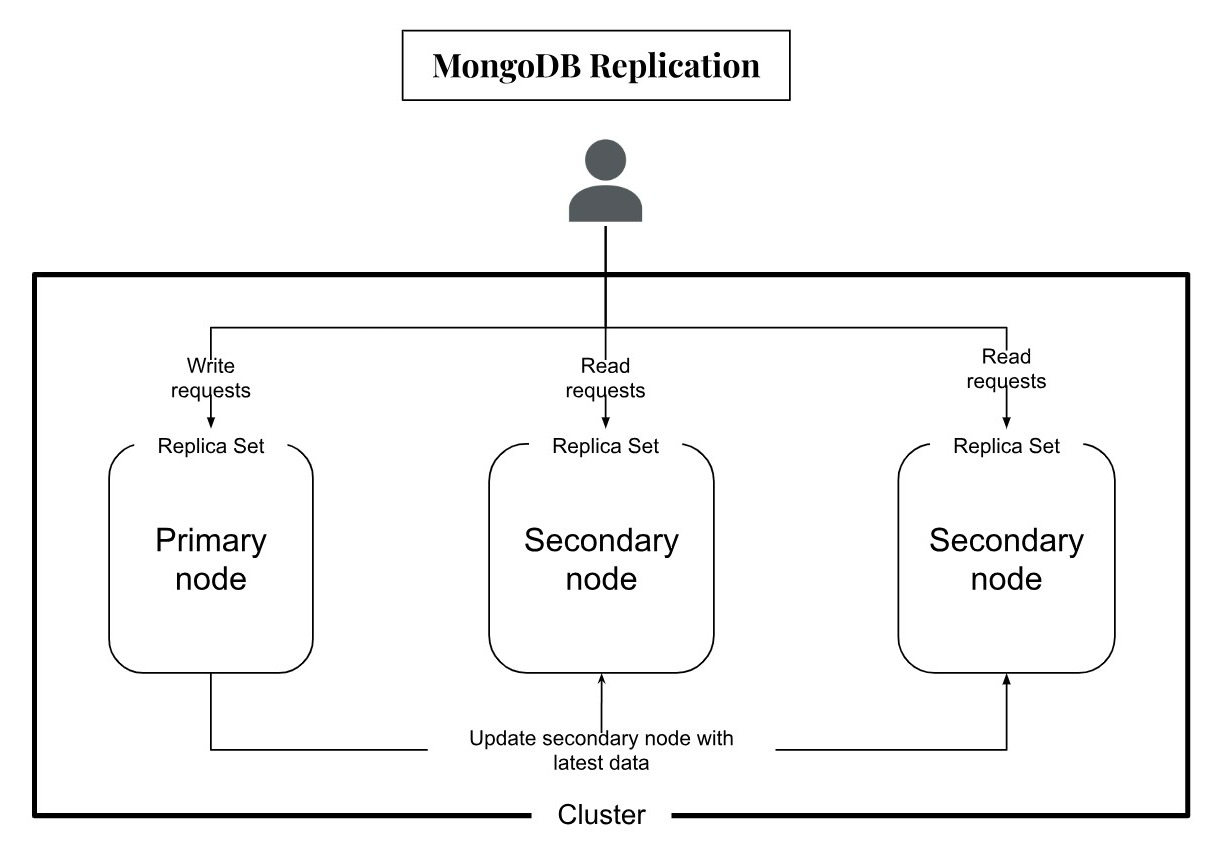
Replication is very useful in case of a hardware crash or even data loss, however the total storage capacity of the database remains the same. Further, there is only one node that can handle write requests, which might create a replication lag, if there are extensive writes required by an application.
MongoDB provides several parameters to help you understand the cause of the replication lag (i.e. updating data from primary to secondary replica sets), like mongostat and write concern.
To learn how to enable replication in MongoDB, you can visit the MongoDB Replication page.
Sharding
Sharding, also known as data partitioning, distributes the data across different nodes in a cluster. The problems posed by replication i.e. the lag due to writes, and the overall increase in capacity are solved using sharding.
As the data is partitioned, each node (or shard, in this case) stores only a part of the complete data and is responsible for reads and writes only for that part of the data. This way you can scale the storage capability of a cluster limitlessly, and enhance the processing capacity of reads and writes too.
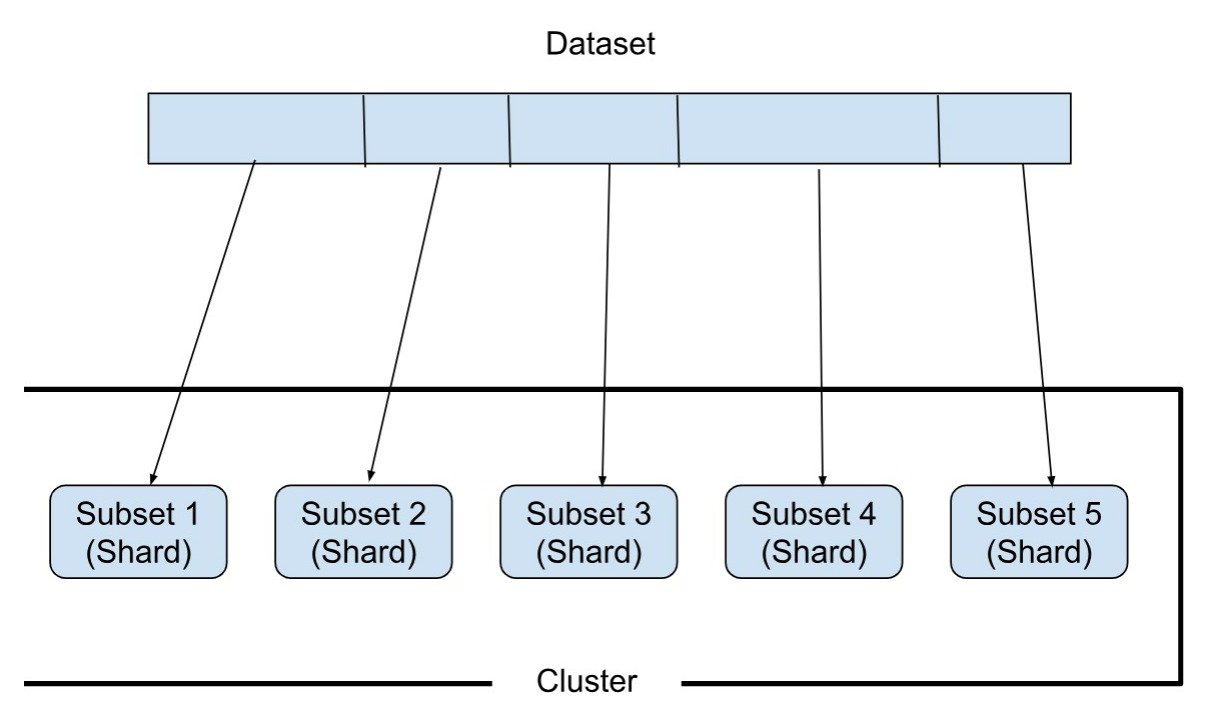
How the dataset is divided into shards depends on the sharding strategy, i.e. a shard key, which you can create while sharding a collection. Note that in a database, you can define sharded as well as non-sharded collections.
It is important to choose the shard key carefully, as the wrong choice would choke the best of the infrastructure and hardware. MongoDB supports two strategies for sharding -
Hashed sharding: Here MongoDB computes the hash value of the shard key field’s value.
Ranged sharding: Here data is divided into ranges based on the shard key values.
Easier said than done, sharding involves splitting data into multiple nodes, which means more servers required to accommodate additional data. This requires a good amount of infrastructure setup, adding to the cost. Also, for each request, MongoDB (or any sharded database) needs to identify which node contains the data and route the request appropriately. Also, if a read requires data from multiple nodes, those have to be combined into a final query resultset before sending the final response.
However, this also means that reads and writes can happen in parallel, thus giving a major boost to the application performance.
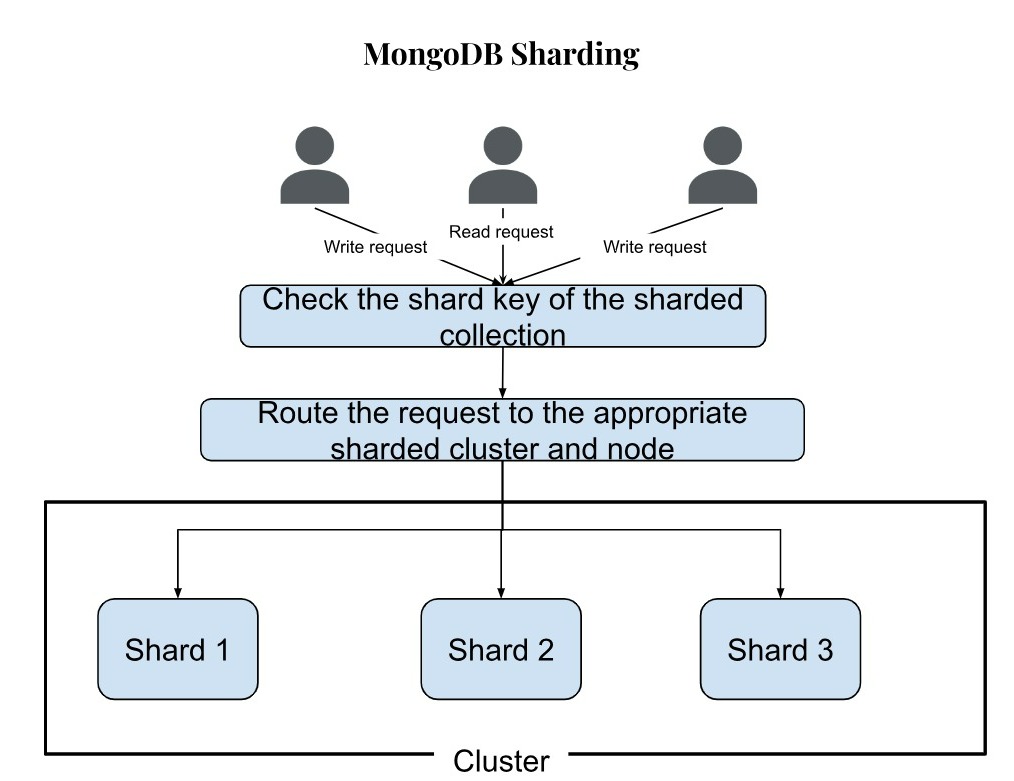
MongoDB Atlas provides a simple and efficient sharded cluster implementation. You can simply use the UI to select the configuration (example, number of shards) you want for your application.
Sharding still provides high availability, as if one part (or shard) of the database goes down, you still have the other parts up and running.
You can learn more about MongoDB sharding from the MongoDB documentation page.
Consistency vs Availability
A distributed system is known to most likely only deliver two of the three important characteristics - Consistency, Availability and Partitioning (CAP) of the database.
While we scale databases to provide high availability, it is important to note that creating a balance between consistency and availability is quite challenging, especially in a distributed environment. We have seen in both the above methods, how a node failover, or an intense write operation can lead to lags and data inconsistency. Most of the time, there is a trade-off between consistency and availability to strike the balance.
However, data critical applications, such as a banking application, need the system to be fast, accurate and available!
MongoDB allows you to customize these parameters by adjusting the read and write preferences, to ensure maximum availability while ensuring there is no compromise on the consistency and data partitioning. Even in the case of replication, if the primary node goes down, the secondary node with the most recent operation log acts as the primary - however all the write operations are stopped for the interval, making sure there are no inconsistencies.
Auto scaling in MongoDB
MongoDB Atlas supports auto-scaling, where you can vertically scale the cluster depending on your cluster usage. You can scale the cluster-tier (i.e. the CPU power) and the storage both, by using the Atlas UI. You can also pause a cluster. Auto-scaling removes the need for writing scripts to configure your clusters manually every time.
Conclusion
In this article, we have seen the basics of scaling, both vertical and horizontal, and learnt the advantages and limitations of each type. We further dived into replication and sharding, two offerings provided by MongoDB, for horizontal scaling, and understood how each of them works, their benefits and limitations. MongoDB Atlas, the developer data platform, provides many features that can make database management quite easy and efficient for you, so you can focus more on the business than worrying about the infrastructure, storage, and other hardware issues.





